
이 글은 한성대학교의 황기태 교수님의 지도를 받아 진행하는 지식 그래프를 활용한 프로젝트 준비 과정을 담은 글이다. 정확한 주제가 정해진 것은 아니지만, Microsoft의 GraphRAG를 활용할 것으로 예상되어 Microsoft에서 제공하는 공식 문서를 중심으로 포스팅하고자 한다.🙌
1. Get Started
MS(Microsoft)에서 요구하는 파이썬 버전은 Python 3.10-3.12이다.
1.1 VS Code 파이썬 버전 확인
VS Code에서 파이썬 버전을 확인하는 방법은 그림 1과 같이 터미널에서 python --version을 치면 된다.
1.2 VS Code 파이썬 버전 변경
VS Code에서 파이썬 버전을 변경하려면 Ctrl+Shift+P를 눌러 명령어 실행창을 띄우고 Python: Select Interpreter를 선택하여 원하는 파이썬 버전을 선택할 수 있다.
2. Top-Level Modules
GraphRAG에서 제공하는 Top-Level 모듈로는 2가지가 있다.
2.1 GraphRAG Indexing🤖
GraphRAG Indexing 패키지는 LLM을 사용해서 구조화되지 않은 텍스트로부터 유의미하고 구조화된 데이터를 뽑아내는 데이터 파이프라인(data pipeline) 및 변환 모음(transformation suite)이다.
Q. '데이터 파이프라인'이란?
A. 데이터를 수집, 처리, 저장, 분석하는 일련의 과정 또는 워크플로우를 의미한다.
MS에서 제공하는 표준 Indexing Pipeline은 다음과 같이 구성되어 있다.
- 텍스트에서 엔터티, 관계 및 클레임 추출
- 엔터티에서 커뮤니티 감지
- 다양한 수준의 세부성으로 커뮤니티 요약 및 보고서 생성
- 그래프 벡터 공간에 엔터티 내장
- 텍스트 벡터 공간에 텍스트 청크 내장
파이프라인의 출력은 JSON, Parquet 등 다양한 형식으로 저장할 수 있다.
Q. '커뮤니티'란?
A. 서로 관련된 노드들의 그룹을 지칭한다.
2.2 Query Engine🔎
Query Engine은 GraphRAG 라이브러리의 검색 모듈이다. Query Engine은 다음과 같은 작업을 수행한다.
- Local Search
- Global Search
Question Generation
1) Local Search: Entity-based Reasoning
Local Search는 지식 그래프의 구조화된 데이터와 입력 문서의 비구조화된 데이터를 결합하여, 질문 응답 시간(query time)에 관련 엔티티 정보를 사용해 대형 언어 모델(LLM)의 문맥을 보강한다. 입력 문서에 언급된 특정 엔티티의 이해를 요구하는 질문에 적절하다. (ex. 캐모마일의 효능이 무엇인가요?)
The local search method combines structured data from the knowledge graph with unstructured data from the input documents to augment the LLM context with relevant entity information at query time. It is well-suited for answering questions that require an understanding of specific entities mentioned in the input documents.

사용자 쿼리와 선택적으로 대화 기록이 주어지면, Local Search는 사용자 입력과 의미적으로 관련된 지식 그래프의 엔티티 세트를 식별한다. 이 엔티티들은 지식 그래프에 접근할 수 있는 지점으로 작용하고, 연결된 엔티티, 관계, 공변량, 커뮤니티 리포트와 같은 추가적인 관련 세부 정보도 추출할 수 있게 한다. 또한, 식별된 엔티티와 연관된 Raw 입력 문서에서 관련 텍스트 조각도 추출한다. 그 다음 이 후보 데이터 소스들은 문맥 창에 맞도록 우선 수위를 매기고 필터링되며, 이를 사용해 사용자 쿼리에 대한 응답을 생성한다.
Given a user query and, optionally, the conversation history, the local search method identifies a set of entities from the knowledge graph that are semantically-related to the user input. These entities serve as access points into the knowledge graph, enabling the extraction of further relevant details such as connected entities, relationships, entity covariates, and community reports. Additionally, it also extracts relevant text chunks from the raw input documents that are associated with the identified entities. These candidate data sources are then prioritized and filtered to fit within a single context window of pre-defined size, which is used to generate a response to the user query.
구성 요소는 다음과 같다.
llm: 응답 생성에 사용할 OpenAI 모델 객체context_builder: 지식 모델 객체 컬렉션(collections of knowledge model objects)에서 컨텍스트 데이터를 준비하는데 사용되는 컨텍스트 빌더 객체system_prompt: 검색 응답을 생성하는 데 사용되는 프롬프트 템플릿, 기본 템플릿 바로가기response_type: 원하는 응답 유형 및 형식을 설명하는 자유형 텍스트llm_params: LLM 호출에 전달될 추가 매개변수(예: 온도, max_tokens)의 사전context_builder_params: 검색 프롬프트에 대한 문맥을 구성할 때context_builder객체에 전달할 추가 매개변수의 사전callbacks: 선택적으로 사용할 수 있는 콜백 함수들로, LLM의 완료 스트리밍 이벤트에 대한 사용자 정의 이벤트 핸들러를 제공하는 데 사용
2) Global Search: Whole Dataset Reasoning
기존 RAG는 답변을 만들기 위해 전체 데이터셋에서 정보를 종합하는 쿼리에 대해 어려워한다. "데이터에서 상위 5개의 주제는 무엇인가요?"와 같은 쿼리는 데이터셋에서 의미적으로 비슷한 텍스트 내용을 벡터 검색에 의존하기 때문에 매우 잘못된 결과를 수행한다.
하지만 GraphRAG를 사용하면 이러한 질문에 답변할 수 있다. 왜냐하면 LLM이 생성한 지식 그래프는 데이터셋의 전체 구조에 대해 알려주기 때문이다. 이를 통해 프라이빗한 데이터셋이 미리 요약된 의미 있는 클러스터로 조직된다. 글로벌 검색 방법을 사용하여, LLM은 사용자 쿼리에 응답할 때 클러스터를 사용해 주제들을 요약한다.
Baseline RAG struggles with queries that require aggregation of information across the dataset to compose an answer. Queries such as “What are the top 5 themes in the data?” perform terribly because baseline RAG relies on a vector search of semantically similar text content within the dataset. There is nothing in the query to direct it to the correct information.
However, with GraphRAG we can answer such questions, because the structure of the LLM-generated knowledge graph tells us about the structure (and thus themes) of the dataset as a whole. This allows the private dataset to be organized into meaningful semantic clusters that are pre-summarized. Using our global search method, the LLM uses these clusters to summarize these themes when responding to a user query.
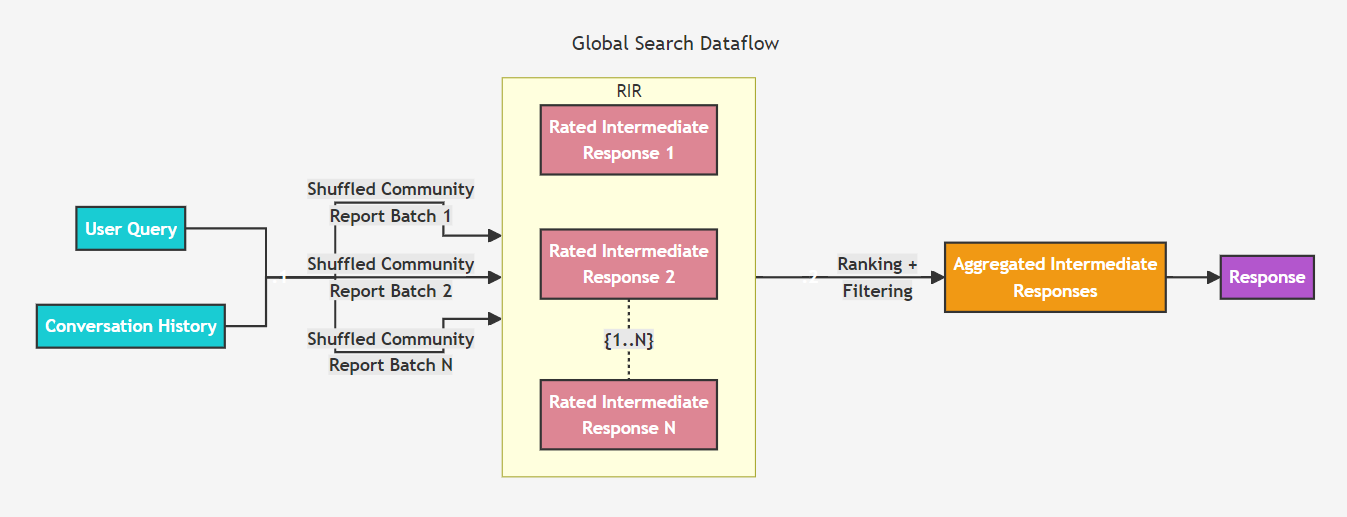
사용자 쿼리와 선택적으로 대화 기록이 주어지면, Global Search 방법은 그래프의 커뮤니티 계층에서 지정된 레벨의 LLM(대형 언어 모델) 생성 커뮤니티 리포터들을 문맥 데이터로 사용하여 map-reduce 방식으로 응답을 생성합니다. map 단계에서는 커뮤니티 리포터들이 미리 정의된 크기의 텍스트 조각으로 분할됩니다. 각 텍스트 조각은 중간 응답을 생성하는 데 사용되며, 이 중간 응답은 각각의 포인트에 대해 그 중요도를 나타내는 숫자 평가와 함께 제공됩니다. reduce 단계에서는 중간 응답들에서 가장 중요한 포인트들을 선별하여 최종 응답을 생성하는 문맥으로 사용됩니다.
글로벌 검색의 응답 품질은 커뮤니티 리포터를 수집하는 데 사용된 커뮤니티 계층의 레벨에 크게 영향을 받을 수 있습니다. 하위 계층의 보고서는 더 상세한 내용을 담고 있어 더 철저한 응답을 제공할 수 있지만, 보고서의 양이 많아짐에 따라 최종 응답을 생성하는 데 필요한 시간과 LLM 자원이 증가할 수 있습니다.
Given a user query and, optionally, the conversation history, the global search method uses a collection of LLM-generated community reports from a specified level of the graph's community hierarchy as context data to generate response in a map-reduce manner. At the map step, community reports are segmented into text chunks of pre-defined size. Each text chunk is then used to produce an intermediate response containing a list of point, each of which is accompanied by a numerical rating indicating the importance of the point. At the reduce step, a filtered set of the most important points from the intermediate responses are aggregated and used as the context to generate the final response.
The quality of the global search’s response can be heavily influenced by the level of the community hierarchy chosen for sourcing community reports. Lower hierarchy levels, with their detailed reports, tend to yield more thorough responses, but may also increase the time and LLM resources needed to generate the final response due to the volume of reports.
3. Overview
MS에서 제공하는 GraphRAG 시스템을 사용하여 간단한 end-to-end 예제를 해보고자 한다. 어떻게 텍스트를 index 하고 index된 데이터를 질문에 답변하기 위해 어떻게 사용되는지 보여준다.
3.1 Install GraphRAG
graphrag를 다음 코드로 설치해보자.
pip install graphrag
이미 설치해둬서 Requirement already satisfied 라고 뜨는 것이다.
3.2 Running the Indexer
샘플 데이터 세트를 넣기 위해 ragtest > input 폴더를 만든다.
mkdir -p ./ragtest/input
Charles Dickens의 A Christmas Carol 사본을 input 폴더에 저장한다.
curl https://www.gutenberg.org/cache/epub/24022/pg24022.txt > ./ragtest/input/book.txt
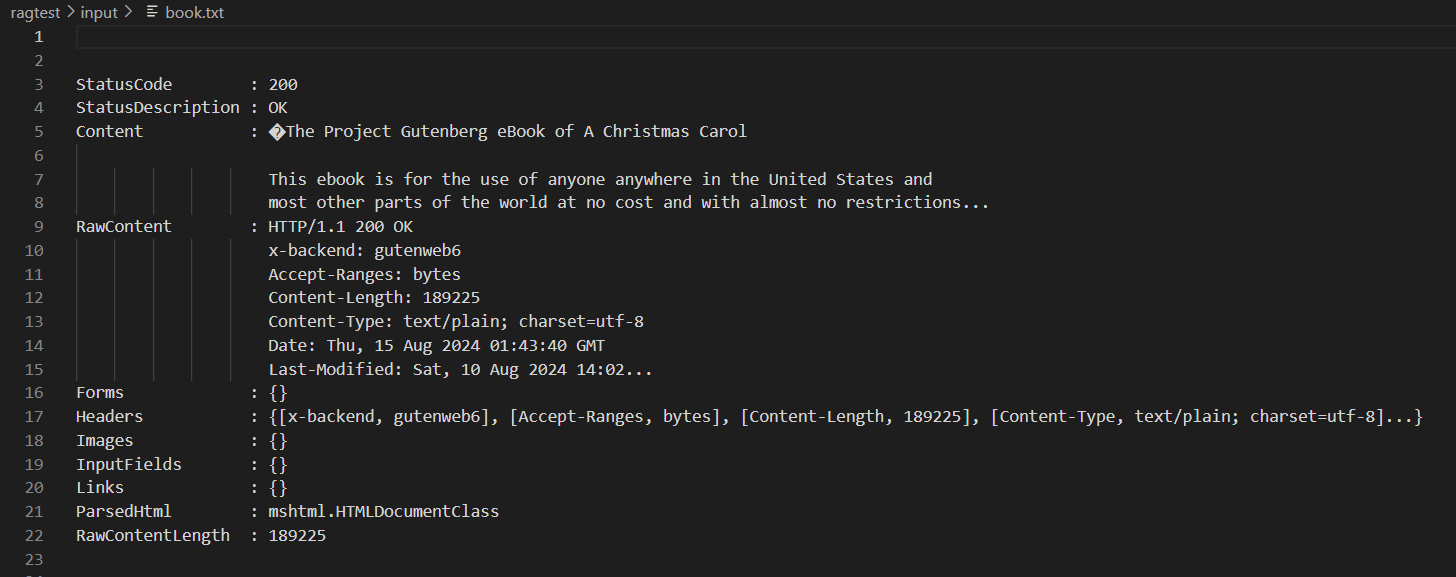
받아온 내용을 보면 다음과 같다. 밑에서 언급하겠지만, book.txt 내용이 잘못되어 아래 Error 1.에서 다시 수정한다.
3.3 Set Up Your Workspace Varibales
먼저, 필요한 환경 변수를 설정해야 한다. 환경 변수에 대한 자세한 내용과 사용 가능한 환경 변수는 다음을 참고하라.
작업 공간을 초기화하려면 graphrag.index --init 명령을 실행해야 한다. 이미 전 단계에서 ragtest라는 디렉토리를 만들었기 때문에 다음 명령을 실행하면 된다.
python -m graphrag.index --init --root ./ragtest
코드를 실행하면 ragtest 디렉토리 안에 다음과 같이 .env와 settings.yaml이 만들어진다.

.env: 이 파일에는 GraphRAG 파이프라인을 실행하기 위한 환경 변수들이 들어있다. 이 파일을 검사하면, 정의된 단일 환경 변수인GRAPHRAG_API_KEY=<API_KEY>를 볼 수 있다. 이것은 OpenAI 또는 Azure OpenAI의 엔드포인트를 위한 API 키이다. 내가 가지고 있는 API 키로 대체할 수 있다.settings.yaml: 이 파일에는 파이프라인 설정이 들어있다. 파이프라인 설정을 바꾸려면 이 파일을 수정하면 된다.
OpenAI와 Azure OpenAI에서 제공하는 OpenAI 모드를 실행하기 위해, .env 파일 안에 있는 GRAPHRAG_API_KEY를 내 API 키로 변경해줘야 한다. OpenAI에서 내 개인 Key를 발급받는 방법을 아래에 설명하겠다.
1. 링크로 들어가서 로그인을 한 후, 오른쪽 상단에 Create new secret key 버튼을 클릭한다.

2. Name에 적당한 이름을 넣고 Create secret key 버튼을 누른다.

3. key를 생성하면 key는 이 화면에서만 보여주고 다시 보여주지 않기 때문에 꼭 저장해두길 바란다.

발급받은 OpenAI 키는 .env 파일에 GRAPHRAG_API_KEY에 다음과 같이 발급받은 자신의 키를 넣어주면 된다.
GRAPHRAG_API_KEY=sk-...5cMA
3.4 Running the Indexing pipeline
이제 파이프라인을 실행시킬 수 있다! 다음 코드를 실행해보자.
python -m graphrag.index --root ./ragtest
❌ Error 1. book.txt 내용 수정❌

에러가 나서 원인을 찾아보니, 사이트에서 가져온 input 디렉토리의 book.txt 내용이 잘못되었다. 원래 내가 가져온 book.txt 내용은 HTTP Response에 대한 내용이 가져와졌다. 하지만 이게 아니라, 정말 그 콘텐츠가 가져와졌어야 했다. 아래 코드로 다시 book.txt를 생성했다.
curl -o ./ragtest/input/book.txt https://www.gutenberg.org/cache/epub/24022/pg24022.txt
실행한 결과, 다음과 같이 사이트의 내용을 그대로 book.txt에 가져온 것을 볼 수 있다.


수정하고 다시 파이프라인을 실행하는 명령어를 쳤는데 또 에러가 났다.
❌ Error 2. ❌
이번에는 그림과 같은 에러가 발생하였다.

Log를 보니 LLM을 부르지 못하는 것 같았다.

OpenAI API 돈을 내니 실행이 잘 된다! 한 번 쓸때마다 대략 $0.05? 정도씩 나가는 것 같다. 다시 인덱싱 파이프 라인을 실행하는 명령어를 치니 잘 실행된다.


이 과정은 실행하는데 시간이 좀 걸릴 수 있다. 입력 데이터의 크기, 사용 중인 모델, 그리고 사용되는 텍스트 청크 크기 등에 따라 달라지고 이 설정들은 settings.yml 파일에서 구성할 수 있다. 파이프라인이 완료되면, ./ragtest/output/<timestamp>/artifacts라는 새로운 폴더에 일련의 파케이(parquet) 파일들이 생성된 것을 볼 수 있다.
3.5 Using the Query Engine
- Global Search 예시
python -m graphrag.query --root ./ragtest --method global "What are the top themes in this story?"
- Local Search 예시
python -m graphrag.query --root ./ragtest --method local "Who is Scrooge, and what are his main relationships?"
MS의 GraphRAG를 해보면서 전체적인 흐름은 이해할 수 있었지만, 시각적으로 지식그래프를 볼 수 없다는 점과, 중간중간 어떤 일이 발생하고 있는지에 대한 과정을 면밀하게 들여다볼 수 없다는 점이 아쉬웠다. 이번 예시를 실행해봄으로써 Neo4j와 연결해서 사용할 수 있는지, 그리고 GraphRAG의 과정을 좀 더 자세하게 이해하고 싶다는 목표가 생겼다.
'Knowledge Graph' 카테고리의 다른 글
| [MS] GraphRAG 사용하기📊 (5) Indexing Dataflow 이해하기 (0) | 2024.09.02 |
|---|---|
| [MS] GraphRAG 사용하기📊 (4) Indexing Architecture 이해하기 (0) | 2024.09.01 |
| [MS] GraphRAG 사용하기📊 (3) 공식 문서 이해하기 (4) | 2024.08.27 |
| [논문 리뷰] Domain-specific Knowledge Graphs: A survey (2) | 2024.08.21 |
| [MS] GraphRAG 사용하기📊 w. Ollama (2) (0) | 2024.08.19 |



